Stable Diffusion 基础使用
前言
由于目前的项目中可能会使用到文生图模型,因此对 Stable Diffusion 的安装与使用进行了些许了解,并记录在本文之中,以便于后续使用。本文中 Stable Diffusion 的安装及 API 调用过程均在 MacOS 系统实现,Windows 系统部分步骤会存在差别。
WebUI 安装步骤
安装 Homebrew
打开终端输入以下命令:
1
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
按提示操作,等待自动安装完成,安装结束会有
Installation successful提示。安装 Python 3.10
打开终端输入以下命令,等待自动安装完成即可:
1
brew install cmake protobuf rust [email protected] git wget
安装 WebUI 软件包
在安装的目标文件夹打开终端,输入以下命令,将代码克隆至本地:
1
git clone https://github.Com/AUTOMATIC1111/stable-diffusion-webui
导入基础模型
Stable Diffusion 生成图形需要先加载基础模型,可登陆 Models - Hugging Face 下载 StabilityAI 官方发布的基础模型。
下载的模型放入 stable-diffusion-webui/models/Stable-diffusion 文件夹中。
启动用户界面
在“终端”中输入以下命令并回车:
1
cd stable-diffusion-webui
然后继续输入
./webui.sh回车,等待运行即可。
ControlNet
ControlNet 的具体作用是什么呢?如果用一句话来介绍 ControlNet,那就是可以实现稳定控图的开源插件。ControlNet 模型可以在使用小数据集进行训练,然后整合任何预训练的 Stable Diffusion 模型来增强模型,来达到微调的目的。
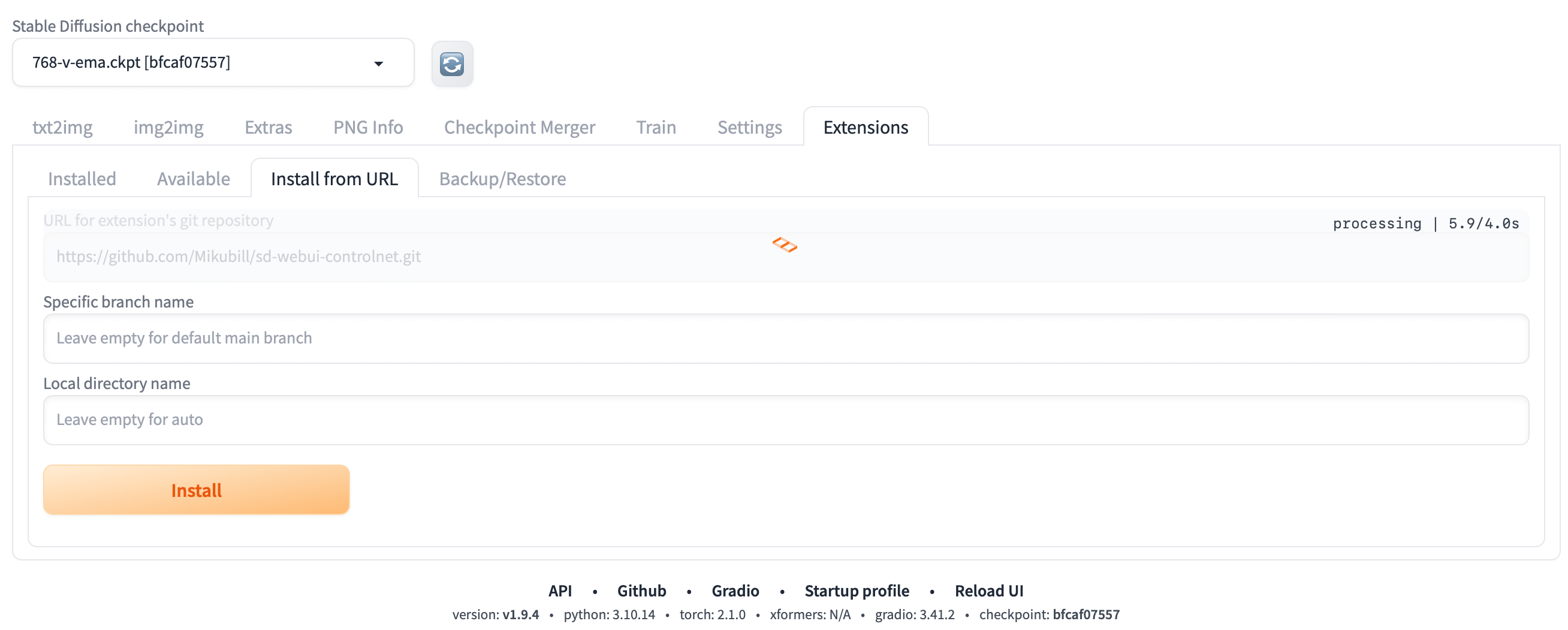
插件安装
我们可以前往 ControlNet 主页进行下载并安装,安装过程可以参考 ControNet 主页的 Installation 部分,也可参考下文:
- 打开 Extensions 中的 Install from URL 选项卡;
- 在 URL for extension’s git repository 处输入 https://github.com/Mikubill/sd-webui-controlnet.git 并点击 Install;
- 等待数秒后,就能够看到消息“Installed into stable-diffusion-webui\extensions\sd-webui-controlnet. Use Installed tab to restart”;
- 打开 Extensions 中的 Installed 选项卡,点击 Check for updates,然后点击 Apply and restart UI(后续更新 ControlNet 使用相同步骤即可);
- 完全重启 webui,包括你的终端;
- 下载模型;
- 将模型放入正确的文件夹后,可能需要刷新才能看到模型。
模型下载
可以前往 ControNet Wiki 的 Model download 页面下载 ControlNet 模型,比如,我选择下载 MEDIUM 模型,需要前往 MEDIUM 模型列表选择模型。
注:和 WebUI 安装过程中下载的模型不同,此处下载的模型要放入 stable-diffusion-webui/extensions/sd-webui-controlnet/models 文件夹中,不要放错位置了!
但列表中有着大量的模型,该如何进行选择呢?首先要了解的是,ControlNet 采用“版本号 + 基础模型版本 + 模控制方式 + 后缀”的命名规则,比如 control_v11f1p_sd15_depth_fp16.safetensors 表示该模型为 v1.1 第一次 bug 修正版的生产就绪版本,基础模型为 Stable Diffusion 1.5,控制方式使用 depth。在 ControNet 模型中比较重要的是控制方式,下面便对各种控制方式进行简单介绍:
Canny 边缘检测模型
该模型使用 Canny 算法检测图像中的边缘线条,通过边缘判断图像主体的范围和轮廓。它可以滤除图像细节,仅保留主要边缘,再根据边缘进行填色。
Depth 深度图模型
该模型可以分析图像中的深度信息,判断不同物体的空间位置关系,如人物与背景的前后位置、手臂在身前身后的位置等。它利用深度学习技术分析 RGB 图像中的立体要素,判断像素的深度差异,从而确定物体的空间布局。常用于人物换背景,调整手臂位置等创意设计。
IP-Adapter 垫图模型
用户能够使用 IP-Adapter 模型通过上传参考图像来生成具有相似艺术风格和内容的作品。其主要功能是通过图像提示来生成图像,能够复制参考图像的风格、构图或人物特征。这种技术不仅可以用于风格迁移,还可以用于面部一致性处理等多种场景。
Inpaint 修补模型
该模型可以对图像进行局部的重绘与修饰,用于小范围的创意设计,如增加色彩、细节等。它可以对指定区域进行处理,保留图像其他部分不变。
Instant-ID 身份标识模型
该模型可以提取人物的面部信息,然后在生成的人物图片中使用此面部。只需要人物的一张正面照片,就可以生成此人物的多种风格图片,适合实现 AI 写真。
InstructP2P 直接编辑模型
该模型可以根据用户输入的文本描述直接编辑图像,如输入“让这栋房子着火”,模型就可以着火处理这栋房子。它需要用户具有一定的创意与想象力,可以实现直接控制生成意想不到的效果。
Lineart 线性检测模型
相较于 Canny 模型,Lineart 模型提取的线稿更加精细,细节更加丰富,适用于产品设计等方面。
MLSD 线性检测模型
该模型也是一款线性检测模型,善于直线线段的提取,比如建筑的线条结构和几何形状,比较适合用于建筑或室内设计风格模型来生成图像。
NormalMap 法线贴图模型
该模型通过检测图像中每个像素的 RGB 颜色值和表面法线方向,来判断物体的边界和明暗部。它可以分离主体和背景,单独控制亮部和暗部的颜色曲线来重绘图像。常用于增加蓝色通道以表现夜晚或日落的色调,或者用于整体图像色彩方面的调整。
OpenPose 人体姿态检测模型
该模型使用深度学习技术检测人体各关键点之间的关节点和运动轨迹,识别人体姿态包括面部和手部运动。它可以处理包含多人的图像,识别每个人物的具体姿态。常用于调整人物手臂位置、生成新表情等创意设计。
Recolor 重新上色模型
该模型可以保持图片的构图,它只会负责上色,图片不会发生任何变化。适合为老旧的黑白照片上色使用。
Reference 参考模型
使得用户能够指定参考图像中期望的属性、构图或风格等属性,然后将这些元素融入到新生成的图像输出中。能够通过该模型保证生成图片的一致性。
Revision 调整模型
该模型能够将图片转换成模型能够理解的概念,可以理解为其具备 prompt 的功能,可以单独使用,也可以结合文字 prompt 附加使用。值得注意的是,Revision 能够把人类或者反推软件忽略的元素也一并转换成模型可以理解的概念,比如 3D 渲染等。
Scribble 涂鸦模型
该模型可以提取用户用户输入手绘的线条、线段等涂鸦,然后可以基于这些输入生成相关的图像输出。
Segmentation 语义分割网络
该模型使用深度学习技术,根据图像中物体的视觉特征将其分割为约 150 种颜色,每个颜色代表一个分类的物体。它可以识别图像中各种要素如天空、建筑、树木等,并单独对每个要素进行处理。常用于单独更改天空颜色或识别树木并修改等。
Shuffle 随机处理模型
该模型可以随机打乱图像的各个要素,包括颜色、形状、构图等,并重新随机组合生成全新的图像。该模型可以提取源图像和参考图像的内容特征和风格特征,将参考图像的风格特征迁移到源图像的内容特征上,生成风格化后的输出图像。
SoftEdge 软线性检测模型
该模型也是一款边缘检测模型,但其生成的线条变得更加柔和,边缘处理更加自然,避免生硬的效果。
SparseCtrl 稀疏控制模型
该模型能够用草图、深度图、关键帧来通过跨帧 attention 生成连续帧,相当于是视频领域的 ContorlNet,唯一的差异是可以在任意指定帧输入指定的约束。通过 SparseCtrl 模型,用户不仅能够自动选择关键帧来介入,降低了资源消耗,还能更灵活地掌控视频生成的过程。
T2I-Adapter 文本到图像模型
该模型可以为预训练的文本到图像(T2I)模型提供额外的指导,同时不影响其原始网络拓扑和生成能力。我们可以利用 T2I-Adapter 模型实现高效可控的文生图技术。
Tile 高清修复模型
该模型将图像分割成多个小块,对每个小块单独进行处理,然后再拼接还原成完整图像。它常用于放大图像时增加细节,或者用于图像修复等场景。分割成小块进行处理可以更好地保留图像细节,避免直接放大导致的线条失真和噪点。
如何生成一张优秀的图像
提示词优化
正向提示词
正向提示词是你希望模型生成图像时所包含的元素。通常情况下,如果你对主体、媒介、风格、色调、画家、光影、额外细节等信息进行详细的描述,得到的结果会远优于只给出主体。另外,越靠前的提示词优先级别一般来说会更高哦!
比如,你希望生成高耸的山脉,你可以使用以下提示词:
1
majestic mountain range with snow-capped peaks, digital painting, realistic style, in the style of romantic landscape, high-resolution, 4K, misty mountain tops with detailed textures, vibrant colors with warm orange and pink hues of sunset, golden hour light casting dramatic shadows
这个提示词会生成一幅具有浪漫主义风格的数字山脉绘画,重点在细节和光影效果,颜色鲜明且分辨率高。而如果你只是输入一个主体
mountain,那么生成的图像往往抽象且模糊!负向提示词
负向提示词是指你希望模型避免生成的元素或特性,通过使用负向提示词,你可以减少或排除不想要的内容。
比如生成人像时,我们会尽量避免不需要的面部特征、低质量的生成、畸形的身体姿势、多余的视觉元素、不合适的艺术风格等等情况,因此需要在负面提示词部分添加以进行规避。比如:
1
bad anatomy, bad face, weird eyes, extra limbs, extra fingers, crooked smile, strange nose, asymmetrical face, missing limbs, deformed hands, low quality, low resolution, blurry, pixelated, grainy, bad proportions, unnatural pose, awkward posture, text, logo, watermark, overexposed, underexposed, too much contrast, unnatural lighting, flat lighting, angry, cartoonish
提示词微调
除了正向提示词与负向提示词以外,还需要了解一些权重语法,这可以用来增强或削弱某些提示词在图像生成中的影响。
加权数值:用
:来指定权重。例如mountain:1.5表示增加“mountain”这个词的权重,模型会更倾向于生成带有山脉的图像。权重默认值为 1,低于 1 的权重会削弱词的影响,高于 1 会增强,比如:1
a beautiful mountain landscape:1.5, sunset:0.8
此时图像会更注重“mountain landscape”部分,而减少“sunset”的影响。
括号法(( ) 和 [ ]):括号内的提示词默认会增加或减少权重。
(提示词)等效于提示词:1.1,而[提示词]等效于提示词:0.9,比如:1
a (beautiful) mountain landscape, [sunset], vibrant colors
此时生成的图像会突出“beautiful”这个词,而“sunset”的影响会变小。
加权数值与括号法能够混合使用,你可以同时为多个正向提示词和负向提示词指定权重,精细控制图像生成过程。
模型选择
你需要根据自己的需求选择合适的基础模型以及 ControlNet 模型,这能够极大的帮助你获得想要的图像生成效果。同时,在 CIVITAI 中,有着大量其他用户训练好的不同风格的模型,你可以在其中选择并下载。
参数调整
采样器(Sampler)
不同的采样器会影响生成图像的质量和风格。常用的采样器有:
- DDIM:通常生成更平滑的图像。
- PLMS:能够更好地处理细节。
- Euler A/B:在多样性和细节上取得良好平衡。
步数(Steps)
调整生成过程中的步数,通常范围在 10 到 100 之间:较少的步数可能会生成更模糊的图像;而较多的步数通常可以提高细节和质量,但会增加生成时间。
3.
API 调用
注:该部分可以参考 Stable Diffusion Wiki 的 API 页面。
当本地部署完成后,需要在启动指令 ./webui.sh 后加上参数 --api,才能调用 Stable Diffusion 的 API:
此时可以访问 http://127.0.0.1:7860/docs 查看 API 文档,其中文生图 API url 为 http://127.0.0.1:7860/sdapi/v1/txt2img,图生图API url 为 http://127.0.0.1:7860/sdapi/v1/img2img。
下面以文生图简单举例,请求参数过于庞大,此处不再列出,大家可以通过 API 文档查看。最简单的请求仅携带 prompt 参数便可进行:
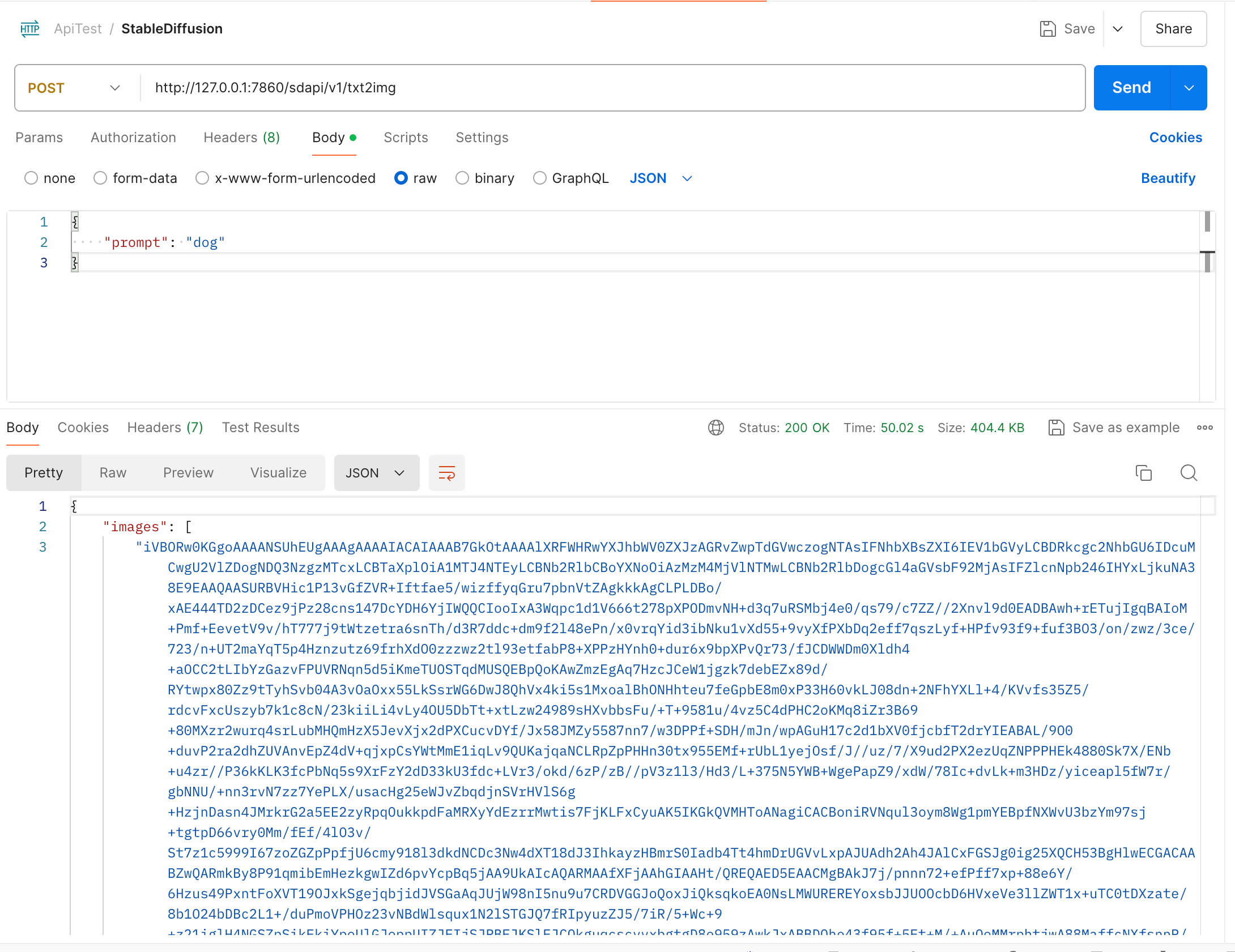
可以看到输出的图片是一个字符串列表 images,后面还包括参数相关结构体 parameters 及字符串 info:
1 | { |
可能你会有点奇怪,图片怎么会是这样的呢?其实,只要将这一大长串字符串使用 Base64 转图片工具进行转换即可得到输出的图片了!调用 API 的步骤就是那么简单!
