Dify 本地部署与使用
前言
Dify 是我实习期间使用的 AI 平台,用起来确实比较舒服,因此在这篇文章中就讲一下本地部署 Dify 及使用的简单流程,作为一个回顾,也为看到这篇文章且想要更好地使用 AI 的朋友们提供方便吧~
注:该文章以 Windows 系统为例!
Dify 介绍
有关 Dify 的基本介绍可以查看 Dify 使用文档,其中提到 Dify 的主要特点为:
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
使用起来能够感觉到比起程序内部直接调用 AI 大模型,Dify 是更加灵活、高效的一种方式。但对于 AI 的使用,LangChain 也是许多开发者会接触到的,那么这两个平台对比,该如何选择呢?
《Dify vs Langchain:AI 应用开发的最佳选择对比》这篇文章已经对两者进行了详细的比较,我这里直接将该文中的对比分析放到下方,便于读者观看:
| 功能 | Dify | LangChain |
|---|---|---|
| 使用简便程度 | 对于初学者和非编码人员来说非常好。视觉界面,最少的编码。 | 需要编码能力。学习曲线较陡,但灵活性更大。 |
| 灵活性和定制性 | 仅限于预构建组件和视觉工作流程。但是,通过配置、自定义代码片段和与外部 API 的集成,它提供了定制选项。 | 通过 Python 代码高度可定制。适用于复杂的 AI 解决方案。 |
| 集成 | 与流行的 AI 模型无缝集成。还支持与 Zapier、Make 等外部工具的集成。 | 集成需要更多的编码工作,但提供了定制模型的灵活性。 |
| 性能和可扩展性 | 适用于大多数应用程序。对于高度复杂或大规模任务可能有限制。 | 可以高效处理复杂的 AI 任务和大型数据集。 |
| 社区和支持 | 不断发展的社区,提供有用的资源。 | 大型、活跃的社区,提供广泛的文档和支持。 |
至于两者如何选择,就需要依具体的使用场景来定了。
本地部署
该部分可以按照 Dify git 仓库中的 Quick Start 进行,以下是较为详细的执行流程。
注:如果只是单纯的想要使用 Dify,且能够连接到外网,可以进入 Dify 官网点击”Get Started“直接使用,不需要再进行本地部署。
Docker 安装
如果电脑上还没有安装 Docker,请先进行此步骤!
首先进入 Docker 官网 进行 Docker 的安装,根据系统选择对应版本的 Docker Desktop,进行安装即可。
镜像源配置
由于国内直接拉取镜像很容易出现“连接错误”等问题,因此需要配置镜像源。如果你没有遇到该问题,可以直接进入下一个部分!
我们可以通过 Docker Desktop 的设置配置镜像源,也可以修改位于 C:\Users\Administrator\.docker 目录下的配置文件 daemon.json(配置文件所在目录可能不同),这里使用修改 Docker Desktop 设置的方式:
打开 Docker Desktop,进入 Settings 中的 Docker Engine,可以看到右方的 json 结构,即为 Docker 的配置文件,我们需要将镜像源列表”registry-mirrors“加入该结构体中,如图所示:
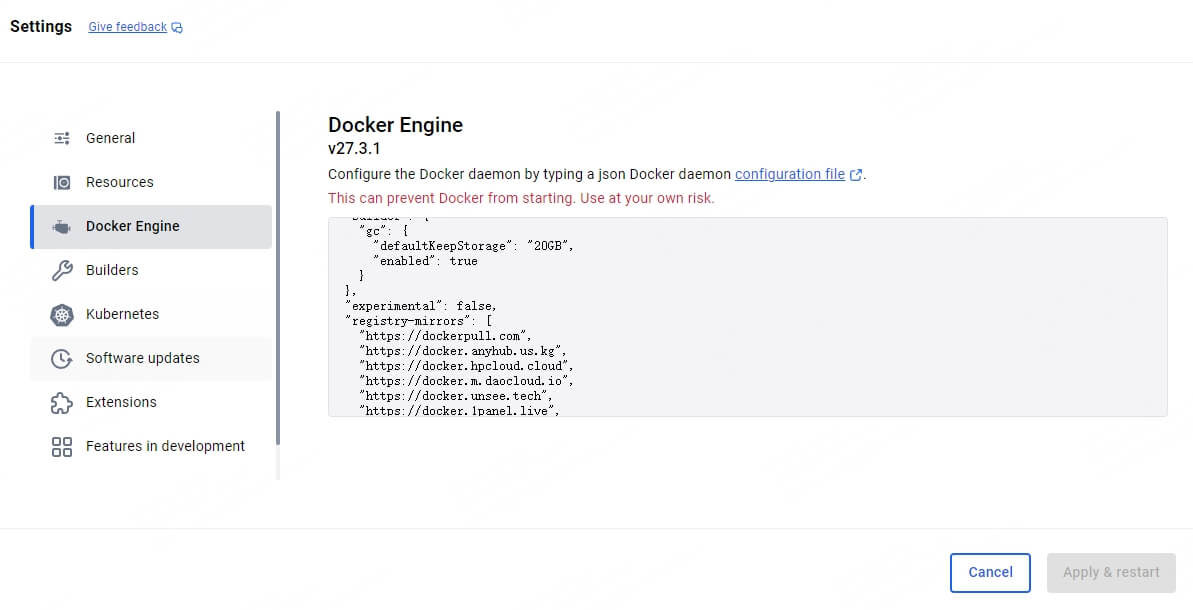
这里是目前能够使用的 Docker 国内镜像源,来源于这篇文章。由于镜像源随时有过期的可能,如果这些不起作用,请寻找其它镜像源。
1 | "registry-mirrors": [ |
我们将该列表放入 json 结构体中,点击”Apply & restart“即可。
拉取 Dify 代码
可以前往 https://github.com/langgenius/dify 手动下载相关部署代码,或者使用 git 命令进行 clone 操作:
1 | git clone https://github.com/langgenius/dify.git |
将文件拉取到本地后,可以看到众多文件,其实我们只需要使用到 docker 目录中的 docker-compose.yaml 文件进行 Docker 部署。
使用 Docker 进行部署
打开 docker 文件夹,进入终端,并输入以下命令:
1 | docker compose up -d |
如果网络正常,等待 Docker 下载并启动所有必要组件即可。
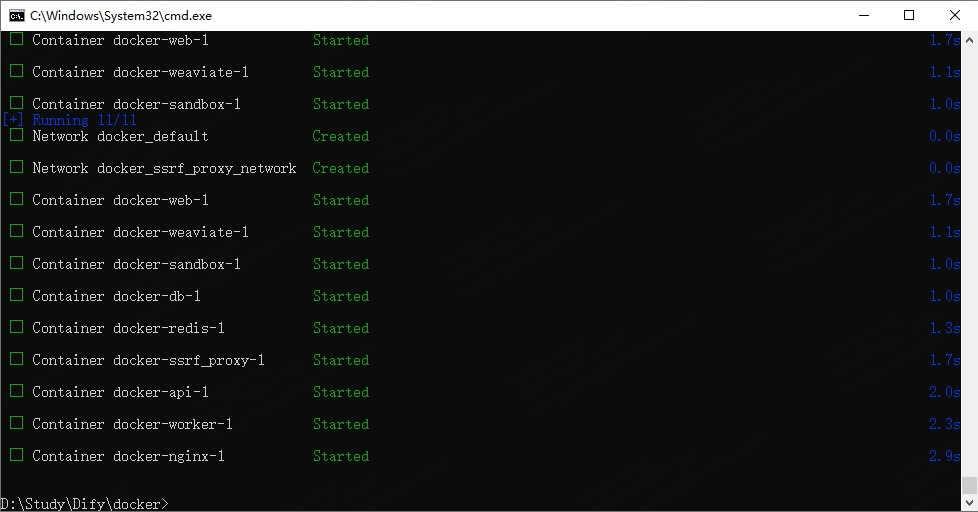
完成后,我们查看 Docker Desktop 中的 Container,会多出来一个名为”docker“的容器:
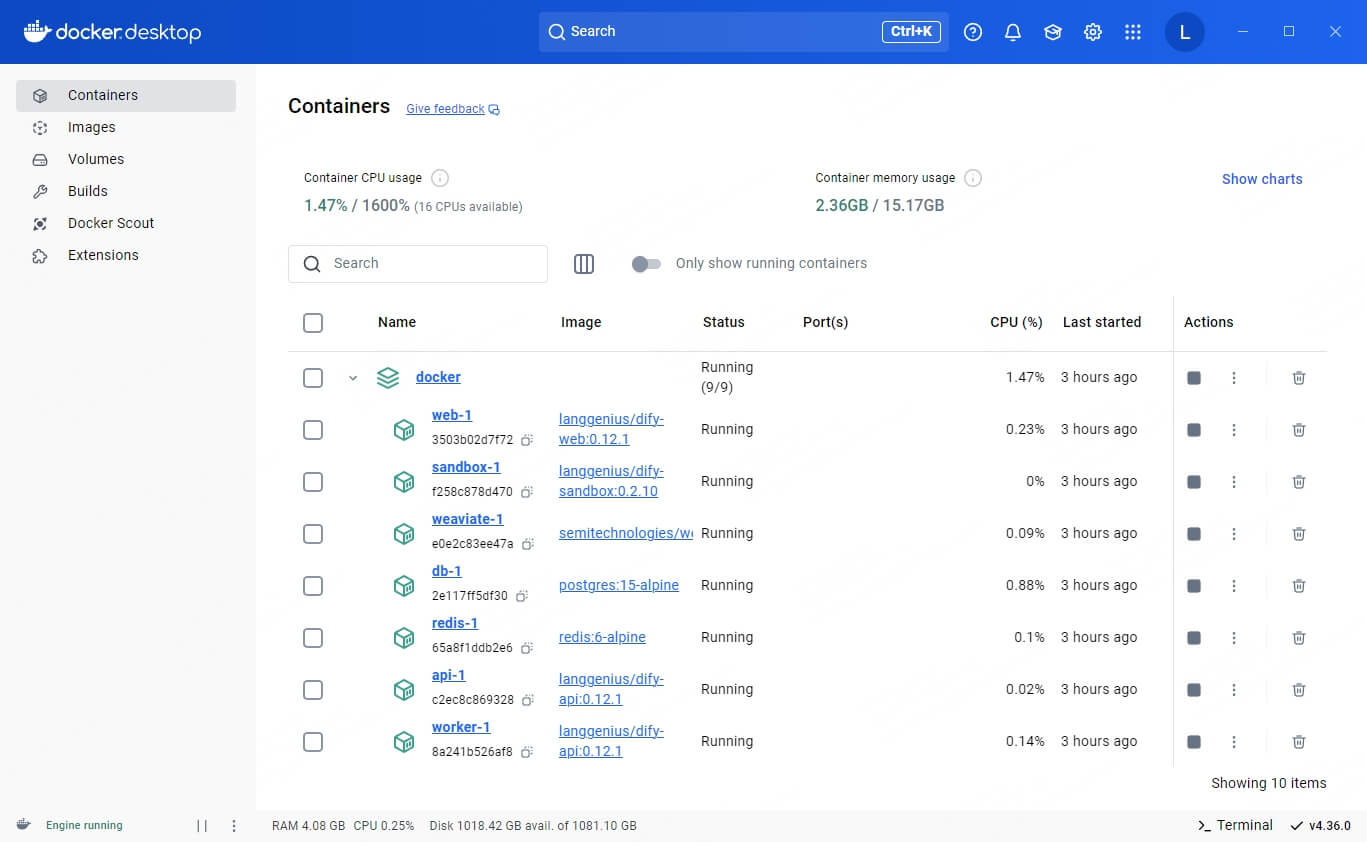
此时我们便可以通过浏览器中输入 localhost/install 来进入设置管理员账户并进行登陆。
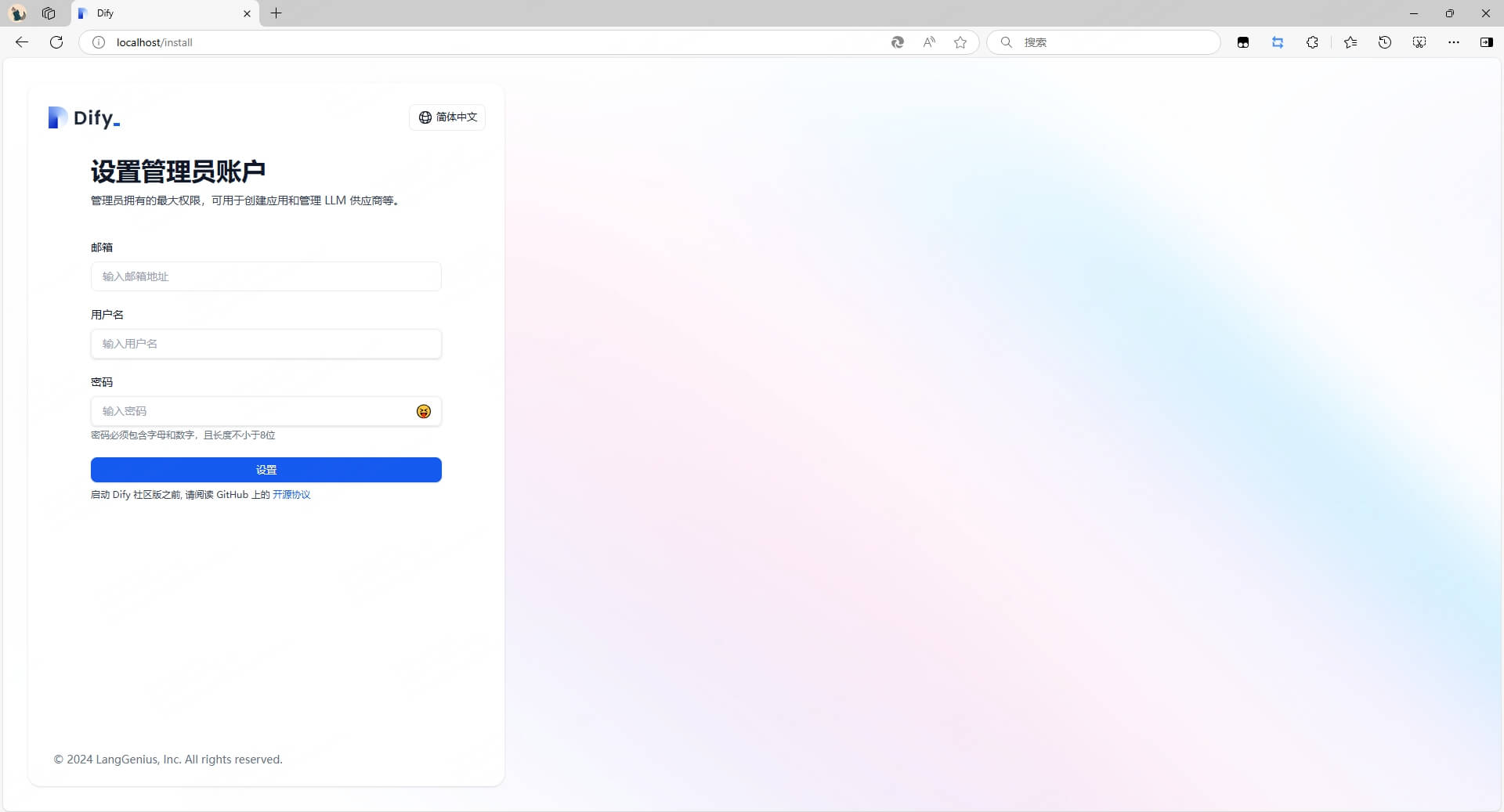
至此,Dify 本地部署已经完成!
Dify 基本使用
本部分主要介绍如何添加大模型以及新建一个简单的工作流应用,其他的使用细节可以参考 Dify 使用文档 进行学习,如果有必要,后续会在本文进行补充。
添加模型
由于 Dify 部署完成后并没有进行大模型的配置,所以此时是无法体验到 Dify 的功能的,该部分就讲述如何将 AI 大模型添加入 Dify。
我们点击右上角账户,进入设置中的模型供应商,可以发现 Dify 支持众多大模型,而你需要获得大模型的 API Key 来添加对应的大模型。
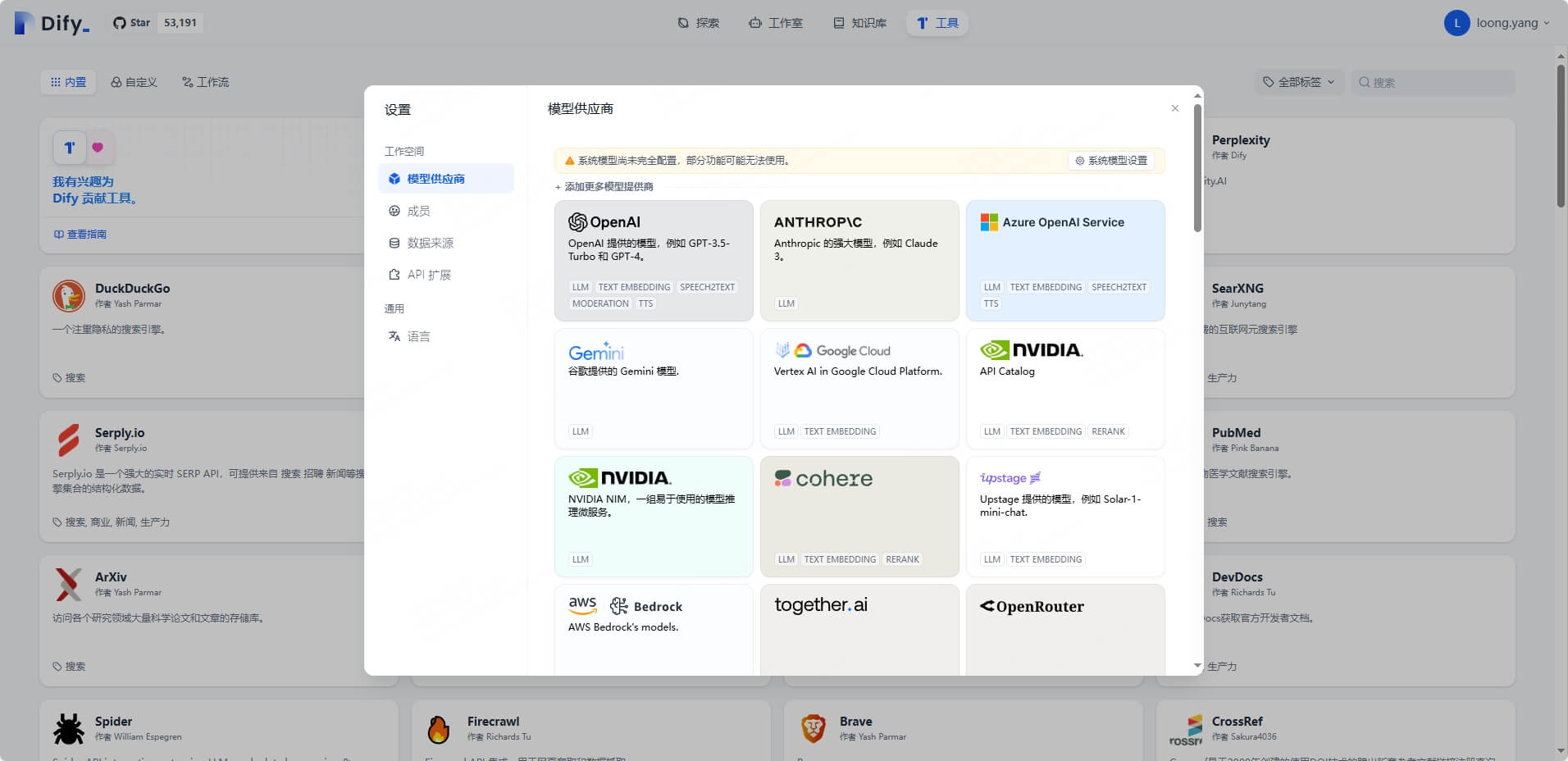
由于阿里云百炼部分模型具有免费额度,因此该部分以通义千问为例:
进入阿里云百炼的模型广场,选择其中一个模型,比如 qwq-32b-preview,点击右上方”查看我的API-KEY“并创建即可;
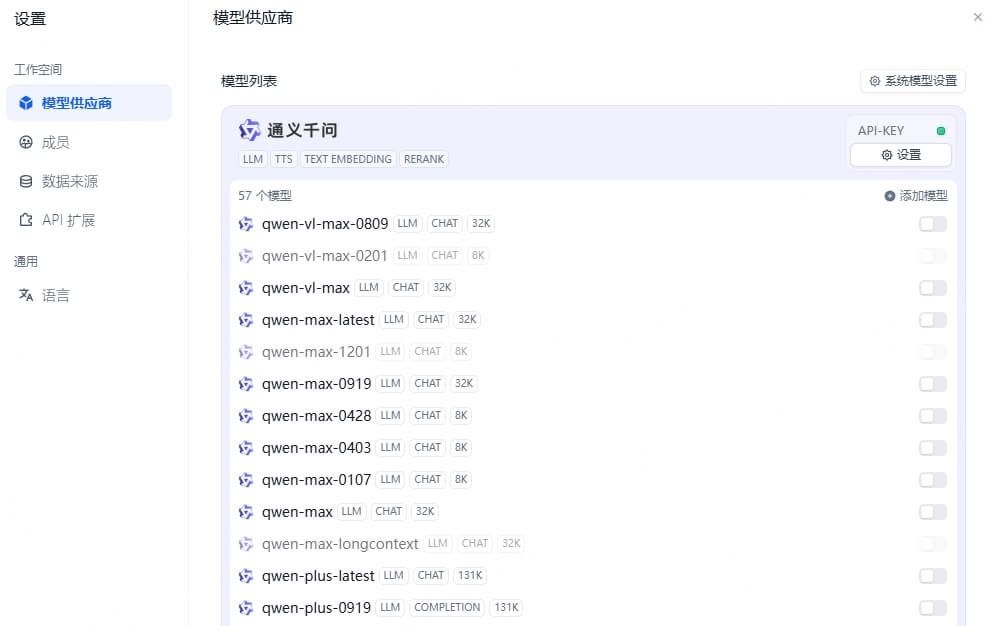
在 Dify 提供的大模型中找到”通义千问“,并点击设置,将得到的 API Key 填入,如果没有出现报错,即可正常使用!你也可以在模型列表中点击”添加模型“,手动添加单个模型,将模型开关打开即可在 Dify 中使用(如图均为关闭状态)。请注意:模型不同,其优势与花费也不同,一定要合理选择!
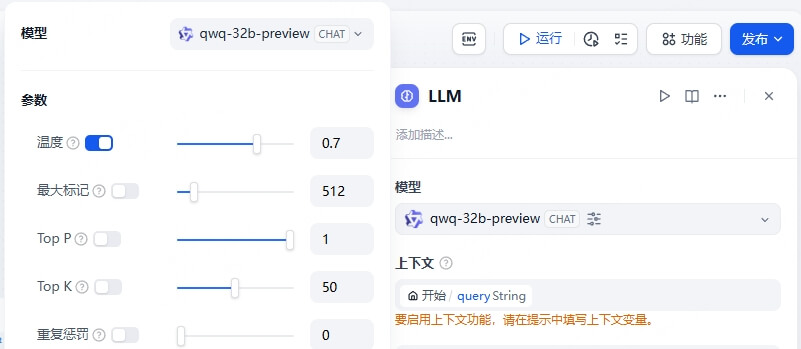
此时便能够为应用中的节点选择模型,参数如无特殊要求保持默认即可,也可查找相关资料进行调整。
新建工作流应用
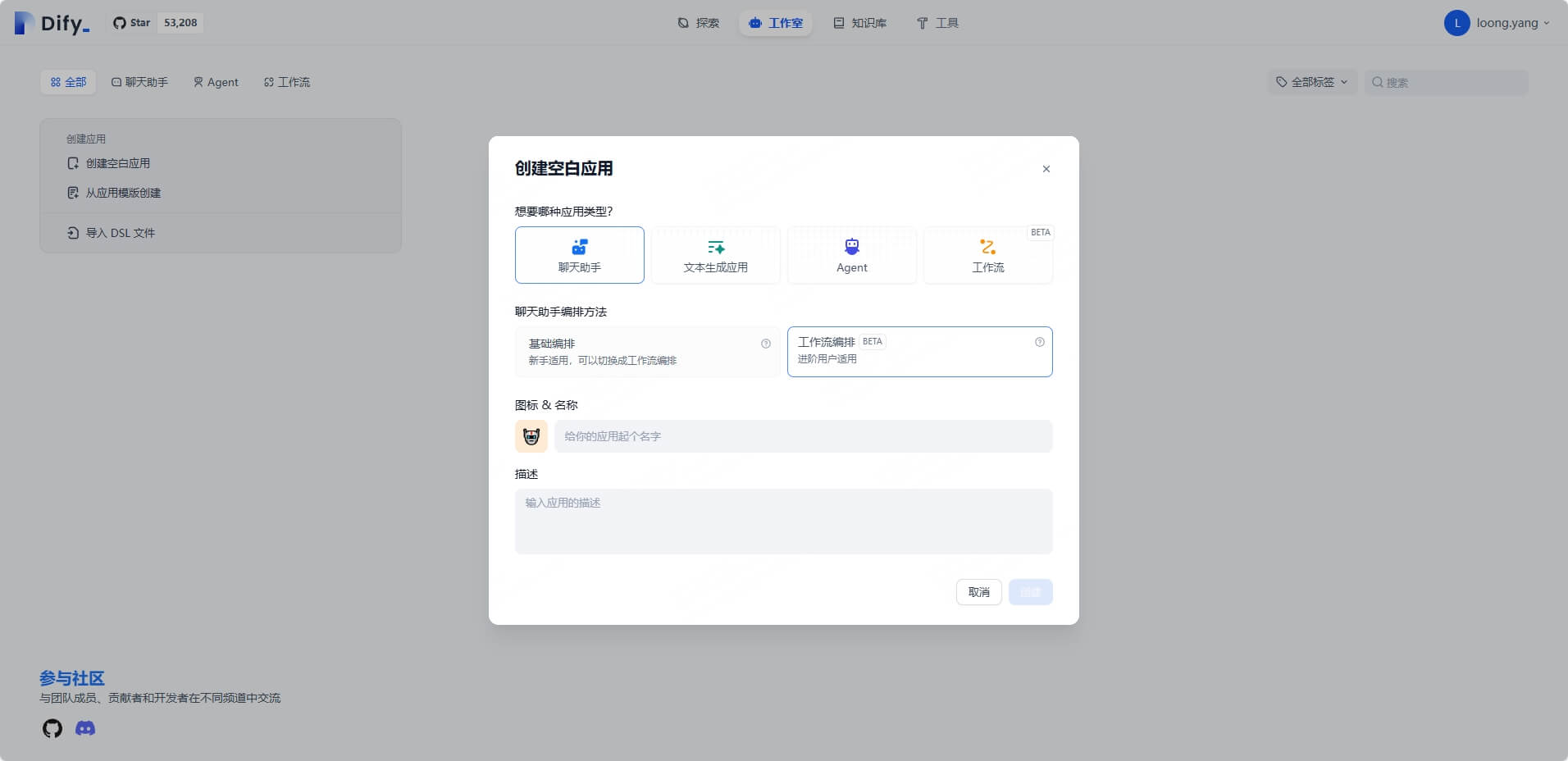
该部分将介绍如何创建一个简单的工作流应用,我们进入 Dify 的”工作室“页面,点击”创建空白应用“,选择”聊天助手“ > ”工作流编排“,起个名字,便能够进行创建啦!
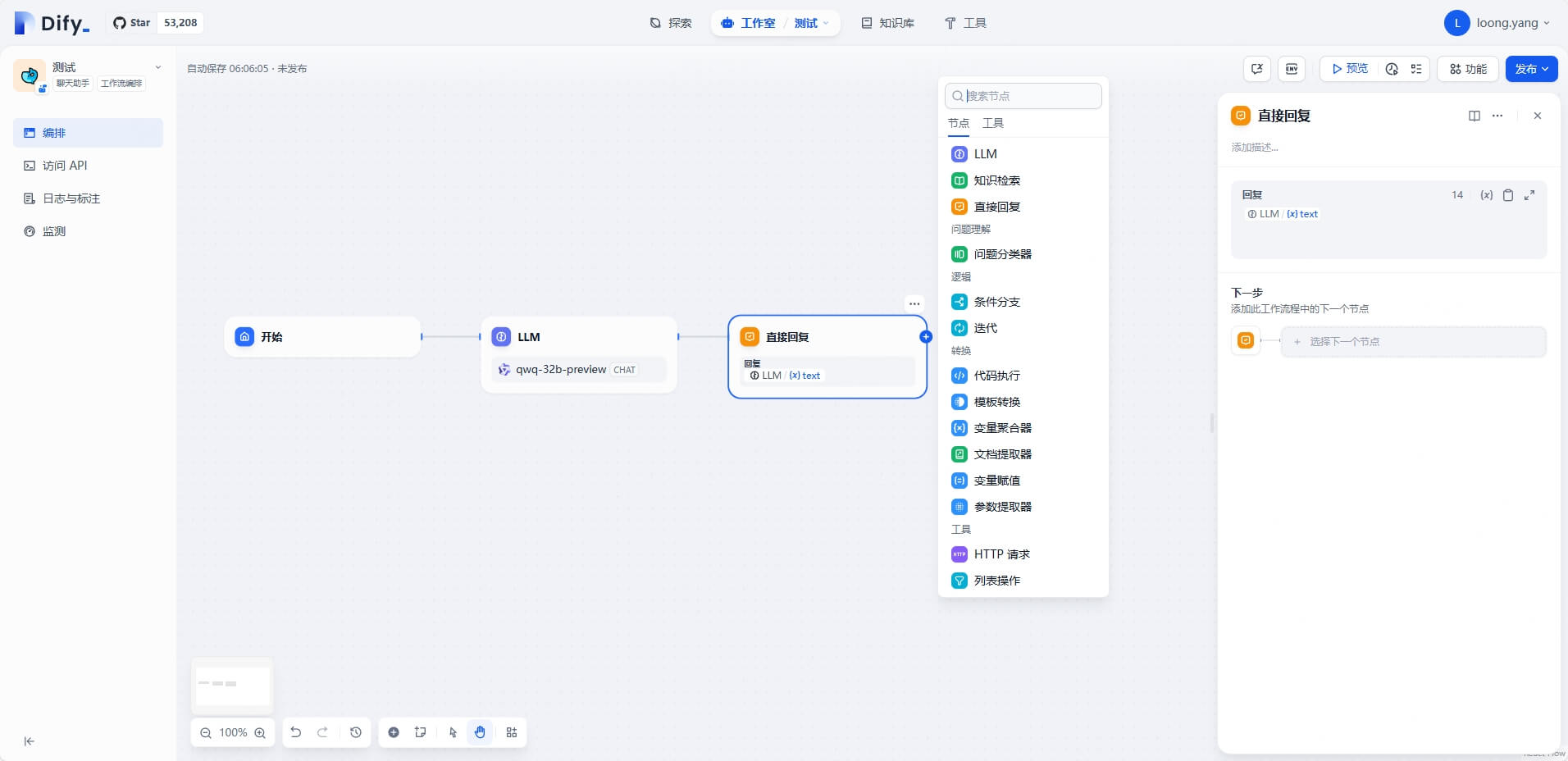
在工作流编排中,我们能够实现许多基础编排无法实现的功能,比如问题分类、代码执行、HTTP请求等,这些都需要通过对应的节点执行。自动生成的基础工作流及可供添加的模块如下图所示:
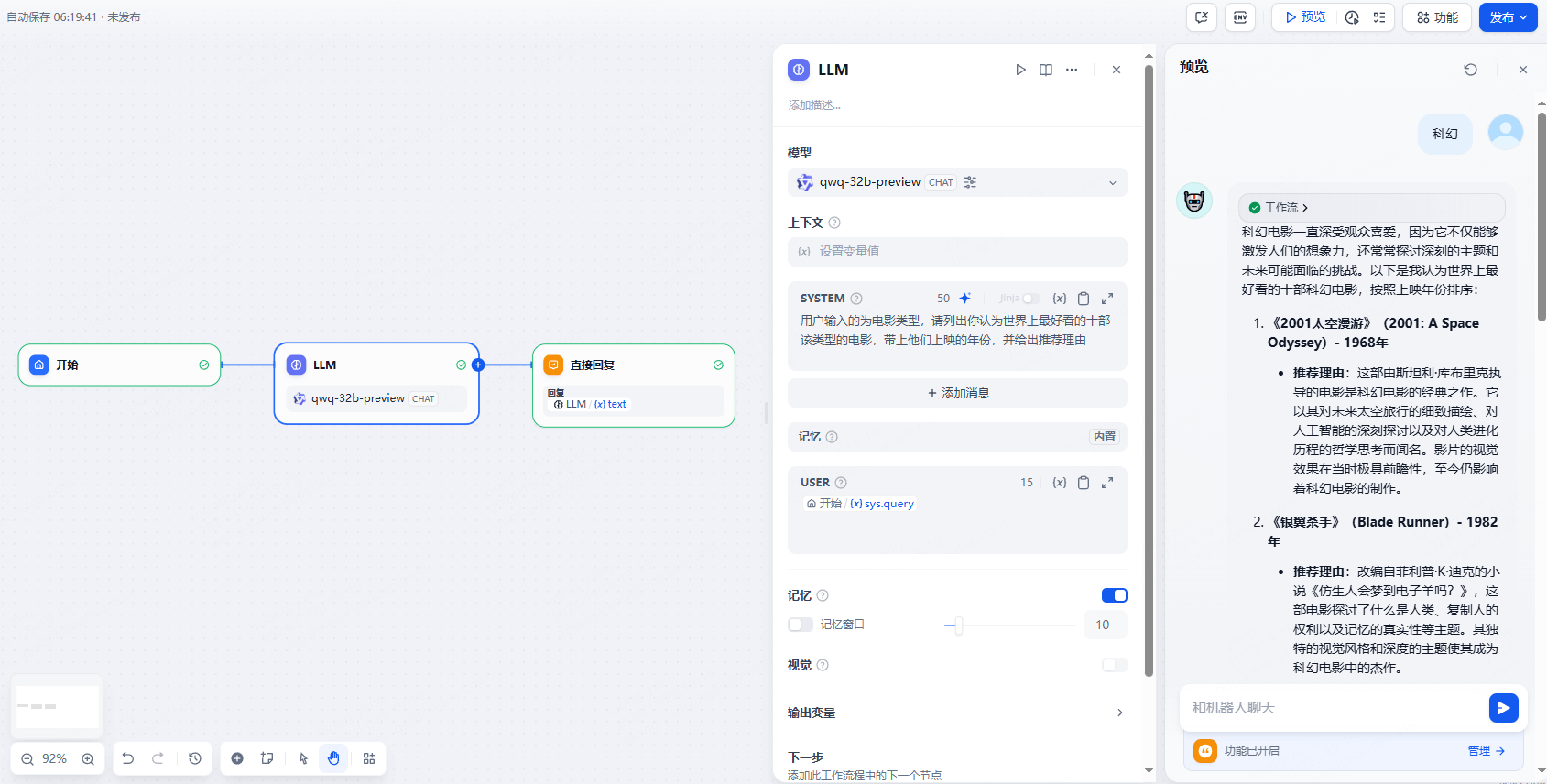
如果我们希望这个工作流在我们输入电影类型时,能够为我们推荐电影,我们能够仅通过以上三个模块来实现,下图即为 LLM 节点的 prompt 及用户输入后得到的回复:
当一切完成后,我们点击”发布“并”运行“,一个 AI 模型 Web UI 服务便搭建完毕啦!
其他
我们还能够通过应用中的”访问 API“来查看如何通过 HTTP 请求访问到我们创建的应用,具体操作就不再赘述啦,不是很难的,大家可以自己摸索,如果有需要我再继续更新~
参考文章
MYSCALE - Dify vs Langchain:AI 应用开发的最佳选择对比
